
Table of content
- Introduction
- Understanding the CAP Attributes
a. Consistency
b. Availability
c. Partition Tolerance - The CAP Trade-offs
a. Consistency and Availability (CA)
b. Consistency and Partition Tolerance (CP)
c. Availability and Partition Tolerance (AP) - Real-World Examples of CAP Trade-offs
a. CA Systems: Relational Databases
i. MySQL
ii. PostgreSQL
b. CP Systems: Distributed Databases
i. Apache ZooKeeper
ii. Google’s Bigtable
c. AP Systems: NoSQL Databases
i. Apache Cassandra
ii. Amazon’s DynamoDB - Factors to Consider when Choosing a Database System
a. Data Consistency Requirements
b. Availability Requirements
c. Network Partition Tolerance
d. Scalability
e. Data Model and Querying Needs - Beyond CAP: Expanding the Scope with the PACELC Theorem
- Conclusion
Introduction
As the digital landscape evolves and data becomes an increasingly valuable asset, distributed databases have emerged as a vital component in managing information across multiple nodes. These databases allow organizations to scale horizontally, increase fault tolerance, and ensure data durability. However, designing and maintaining distributed databases is a complex task, and developers must navigate a myriad of trade-offs to ensure the desired performance, reliability, and consistency.
At the heart of these trade-offs lies the CAP Theorem, a principle formulated by computer scientist Eric Brewer in 2000. The CAP Theorem posits that:
It is impossible for a distributed database system to simultaneously guarantee Consistency, Availability, and Partition Tolerance. Instead, a system can only ensure two out of the three attributes.
This theorem has become a fundamental concept in the design and behavior of distributed databases, shaping the choices developers make when selecting and implementing a system that meets their application’s requirements.
In this article, we will explore the intricacies of the CAP Theorem and its implications on the world of distributed databases. We will delve into each of the CAP attributes, discuss the trade-offs involved, and examine real-world examples to illustrate how these trade-offs manifest in various database systems. We will also outline the factors to consider when choosing a database system for your application and touch upon the PACELC Theorem, which expands upon the CAP Theorem to offer additional insights into distributed database design.
By the end of this article, you will have a solid understanding of the CAP Theorem and its relevance to distributed databases, empowering you to make well-informed decisions when architecting your next data-intensive application.
Understanding the CAP Attributes
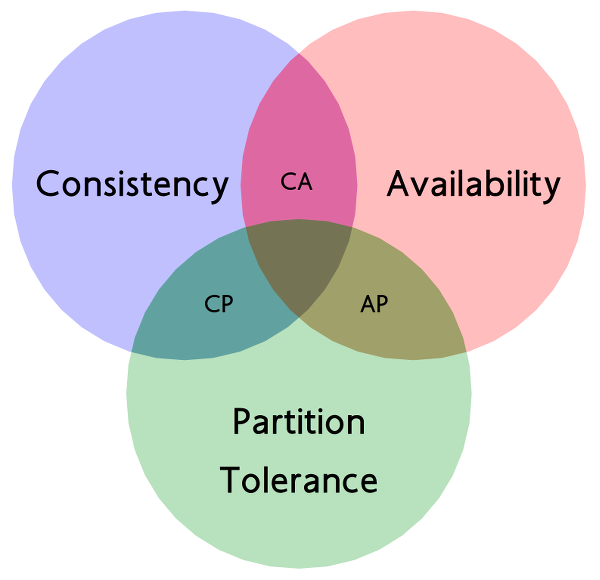
The CAP Theorem revolves around three core attributes: Consistency, Availability, and Partition Tolerance. To fully comprehend the trade-offs involved in the CAP Theorem, it’s crucial to understand what each of these attributes represents.
Consistency
Consistency refers to the property that all nodes in a distributed database have the same data at any given time. This means that every read operation returns the most recent write or an error.
Imagine you and your friends are playing a game where you all need to keep track of the same scores on your phones. If everyone’s phone shows the same score at any given moment, your game is consistent.
Strong consistency is essential for applications that require accurate and up-to-date information, such as financial transactions, inventory management systems, or applications that enforce strict data integrity constraints. Consistency can be further classified into different levels, such as strong, eventual, and causal consistency, each of which has its own trade-offs and implications on system performance.
Availability
Availability denotes the property that every request to the database receives a response, either a success or a failure, without any delay or error. This implies that a system is always operational and accessible to clients, regardless of the internal state of the nodes or the network.
Let’s say you and your friends are using a messaging app to chat. Availability in this context means that whenever you send a message or want to see new messages, the app will always work without any delays or errors.
High availability is crucial for applications that must remain online at all times, such as e-commerce platforms, online gaming services, or mission-critical systems that cannot afford downtime.
Partition Tolerance
Partition tolerance is the ability of a distributed database to continue functioning even in the presence of network failures or communication breakdowns between nodes.
Imagine you and your friends are using walkie-talkies to play a game, but suddenly, some walkie-talkies can’t communicate with the others due to a problem, like going out of range or having low batteries. Still, all the walkie-talkies not having any issues will keep working.
In a partition-tolerant system, the database remains operational and accessible, even when some nodes are unreachable due to network issues, hardware failures, or other disruptions. Partition tolerance is particularly important for applications that rely on distributed databases across multiple geographical locations or within large-scale data centers, where network partitions are more likely to occur.
In short,
Consistency (C): Making sure that everyone has the same information at all times, like the same scores in a game or the same list of friends in a social media app.
Availability (A): Making sure that the system keeps working and responding to requests, like sending messages or posting pictures, no matter what happens.
Partition Tolerance (P): Making sure that the system can keep working even if some computers can’t talk to each other for a while, like when walkie-talkies lose connection.
The CAP Trade-offs
Since we can only choose between Consistency, Availability, and Partition Tolerance, the possible trade-offs are:
Consistency and Availability (CA)
Systems that prioritize consistency and availability ensure that all nodes have the same data at any given time and that every request receives a response. However, these systems sacrifice partition tolerance, meaning they may experience data inconsistencies or become unavailable during network partitions.
Imagine in a game, you have to communicate with each other to solve a puzzle over walkie-talkies. You want to make sure everyone has the same information about the game (Consistency) and can keep playing (Availability), but if there’s a problem with communication, the game might have issues or stop working.
CA systems are suitable for applications where data consistency is critical, and network partitions are either rare or unlikely to occur.
Consistency and Partition Tolerance (CP)
Systems that prioritize consistency and partition tolerance guarantee that data remains consistent across nodes and can handle network failures. However, they may sacrifice availability during network partitions or when some nodes are down.
Imagine you and your friends are playing an online game where it’s crucial for everyone to have the same information, like a virtual treasure hunt. If you choose the CP trade-off, the game will make sure everyone sees the same clues and can keep playing even if some players lose connection. However, there might be moments when the game doesn’t respond immediately or takes some time to update the clues.
CP systems are ideal for applications where data consistency is paramount, and occasional unavailability is tolerable.
Availability and Partition Tolerance (AP)
Systems that prioritize availability and partition tolerance ensure continuous availability and the ability to handle network failures, even when some nodes are unreachable. However, they may temporarily serve inconsistent data.
Imagine you and your friends are using a social media app to chat and share pictures. If you choose the AP trade-off, the app will make sure it keeps working and can handle situations when some phones lose connection. However, there might be moments when some messages or pictures are not immediately visible to everyone, inconsistent, and it takes a little time to update.
AP systems are suitable for applications where continuous availability is essential, and temporary data inconsistencies can be tolerated.
It’s important to note that the CAP Theorem presents a simplified view of distributed databases, and real-world systems may exhibit varying degrees of consistency, availability, and partition tolerance. In practice, some systems attempt to strike a balance between these attributes by offering tunable parameters that allow developers to adjust the trade-offs based on their specific needs. However, the CAP Theorem still provides a valuable framework for understanding the fundamental constraints and challenges that developers face when designing distributed database systems.
Real-World Examples of CAP Trade-offs
To better understand the implications of the CAP trade-offs, let’s examine real-world examples of database systems that prioritize different combinations of Consistency, Availability, and Partition Tolerance.
CA Systems: Relational Databases
a. MySQL: MySQL is a widely used open-source relational database management system (RDBMS) that primarily focuses on consistency and availability. It ensures that data remains consistent across nodes and that the system is highly available. However, MySQL is not inherently designed to handle network partitions. In the event of a partition, the system may experience data inconsistencies or become unavailable, depending on the configuration.
b. PostgreSQL: Another popular open-source RDBMS, PostgreSQL also prioritizes consistency and availability. Similar to MySQL, PostgreSQL provides strong data consistency and high availability but does not inherently handle network partitions well. When a partition occurs, the system may face data inconsistencies or unavailability.
CP Systems: Distributed Databases
a. Apache ZooKeeper: Apache ZooKeeper is a distributed coordination service that prioritizes consistency and partition tolerance. It is designed to manage configuration information, provide distributed synchronization, and maintain a naming registry for distributed systems. In the event of network partitions, ZooKeeper ensures that data remains consistent across nodes, but it may become temporarily unavailable until the partition is resolved.
b. Google’s Bigtable: Bigtable is a distributed storage system designed for handling large amounts of structured data. It prioritizes consistency and partition tolerance, ensuring that data remains consistent across nodes while being able to handle network failures. However, during network partitions or node failures, some parts of the system may become temporarily unavailable.
AP Systems: NoSQL Databases
a. Apache Cassandra: Apache Cassandra is a highly scalable, distributed NoSQL database that prioritizes availability and partition tolerance. Designed for handling massive amounts of data across many commodity servers, Cassandra ensures that the system remains available and operational even during network partitions or node failures. However, it may temporarily serve inconsistent data during such events. Cassandra is ideal for applications that require high availability and can tolerate eventual consistency.
b. Amazon’s DynamoDB: DynamoDB is a managed NoSQL database service provided by Amazon Web Services (AWS). It focuses on providing high availability and partition tolerance, ensuring that the system remains operational even in the presence of network failures or node disruptions. However, DynamoDB may temporarily serve inconsistent data under these circumstances. Like Cassandra, DynamoDB is well-suited for applications that prioritize availability and can accept eventual consistency.
These examples illustrate how different database systems prioritize various combinations of the CAP attributes based on their specific use cases and requirements. By understanding the trade-offs involved and analyzing the needs of your application, you can make informed decisions when selecting a suitable database system.
Factors to Consider when Choosing a Database System
Selecting the right database system for your application involves considering various factors beyond the CAP Theorem trade-offs. While Consistency, Availability, and Partition Tolerance are crucial attributes, other aspects also play a significant role in determining the most suitable database system for your needs. Here are some factors to consider when making your decision:
- Data Consistency Requirements: Analyze the level of data consistency your application demands. Financial transactions, for example, require strong consistency to maintain data integrity, while social media applications might tolerate eventual consistency for better performance and availability.
- Availability Requirements: Assess the importance of continuous availability for your application. E-commerce platforms and mission-critical systems demand high availability to ensure a seamless user experience and avoid potential revenue loss due to downtime.
- Network Partition Tolerance: Determine the likelihood of network partitions in your application’s environment. Large-scale distributed systems spanning multiple data centers or geographical locations are more susceptible to network failures, making partition tolerance a crucial factor.
- Scalability: Consider the expected growth of your application and the need to scale horizontally (adding more nodes) or vertically (adding more resources to existing nodes). Distributed databases like Cassandra and DynamoDB are designed for horizontal scalability, while traditional relational databases like MySQL and PostgreSQL may require vertical scaling.
- Data Model and Querying Needs: Evaluate the data model and query patterns your application requires. Relational databases typically use structured data and support complex queries, while NoSQL databases cater to unstructured or semi-structured data and offer more flexible querying options.
- Performance: Examine the performance requirements of your application, including read and write throughput, latency, and query optimization. Different database systems have varying performance characteristics based on their architecture, indexing strategies, and caching mechanisms.
- Security and Compliance: Assess the security and compliance requirements of your application, such as data encryption, access control, and auditing. Some database systems provide built-in security features, while others may require additional tools or configurations to meet specific security and compliance standards.
- Ease of Use and Management: Consider the learning curve, administration, and maintenance efforts associated with the database system. Familiarity with a particular technology, community support, and availability of resources like documentation and tooling can influence the ease of use and management of the system.
- Cost: Evaluate the total cost of ownership (TCO) of the database system, including licensing fees, hardware and infrastructure costs, and maintenance expenses. Managed database services, such as Amazon’s DynamoDB or Google Cloud’s Bigtable, may offer cost advantages by offloading operational overhead to the service provider.
By carefully considering these factors in conjunction with the CAP trade-offs, you can make well-informed decisions that best meet the needs of your application and ensure a robust and reliable database infrastructure.
Beyond CAP: Expanding the Scope with the PACELC Theorem
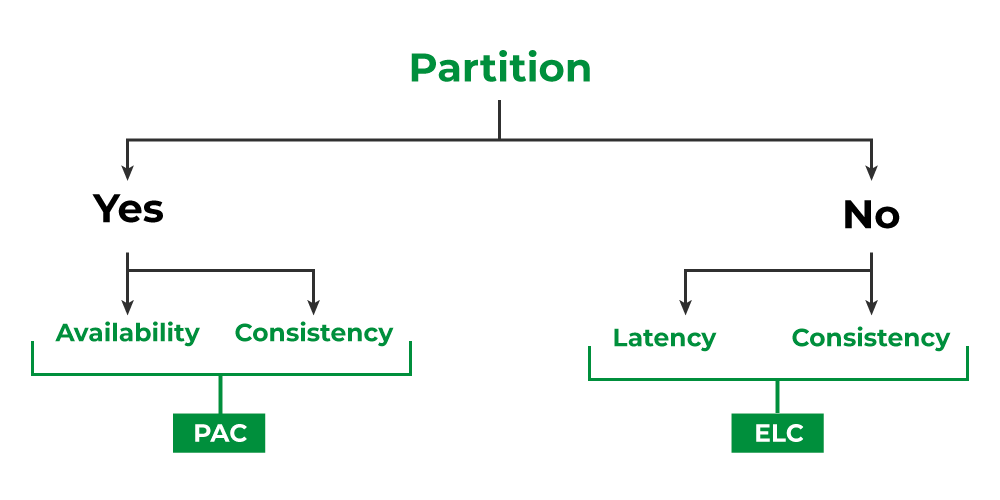
While the CAP Theorem provides a valuable framework for understanding the trade-offs in distributed database systems, it primarily focuses on the behavior of these systems during network partitions. To offer a more comprehensive perspective, the PACELC Theorem expands upon the CAP Theorem by considering both partitioned and non-partitioned scenarios.
The PACELC acronym stands for:
- Partition (P): When a network partition occurs.
- Availability (A): The availability of the system.
- Consistency (C): The consistency of the data across nodes.
- Else (E): When there is no network partition.
- Latency (L): The latency of read and write operations.
- Consistency (C): The consistency of the data across nodes.
The PACELC Theorem essentially posits that a distributed database system must choose between consistency and latency, both when a network partition occurs (P) and during normal operation (E).
In a partitioned scenario (P), the PACELC Theorem aligns with the CAP Theorem, asserting that a system must choose between consistency (C) and availability (A). However, the PACELC Theorem goes further by highlighting the trade-off between consistency and latency during normal operation (E). This means that even in the absence of network partitions, a system must still choose between providing strong consistency at the expense of increased latency or favoring lower latency with potentially weaker consistency guarantees.
In simple words, the PACELC Theorem tells us that we need to choose between having a fast system that responds quickly (low Latency) or a system that always has the same information for everyone (Consistency), even when there are no communication problems.
The PACELC Theorem helps developers and architects better understand the inherent trade-offs in distributed database systems and provides additional insights into the design and behavior of these systems beyond the constraints outlined by the CAP Theorem. By considering the PACELC trade-offs, decision-makers can make more informed choices when selecting a database system that aligns with their application’s performance, consistency, and availability requirements.
Conclusion
The CAP Theorem has been instrumental in shaping our understanding of distributed database systems and the trade-offs involved in their design and implementation. By recognizing the inherent limitations of these systems in providing Consistency, Availability, and Partition Tolerance simultaneously, developers and architects can make informed decisions that best align with their application’s specific requirements.
Furthermore, the PACELC Theorem expands upon the CAP Theorem by considering the trade-offs between consistency and latency in both partitioned and non-partitioned scenarios, providing additional insights into the behavior and performance of distributed databases.
In this article, we have explored the CAP attributes, their trade-offs, real-world examples of various database systems, and the factors to consider when choosing a database system for your application. With this knowledge, you are now better equipped to make well-informed decisions when designing and building your next data-intensive application, ensuring a robust, reliable, and performant database infrastructure that caters to your unique requirements.
Thank you for reading this article. If you like such content, do subscribe to the newsletter.
Post a Comment